本文共 1287 字,大约阅读时间需要 4 分钟。
有时候,我们需要将日志文件中的数据导入到Hbase中,通常情况下,你可以写一个方法逐行读取日志记录然后写入到Hbase中,但是这种方法往往效率比较低下,更好地方式试讲日志文件的内容通过某种工具直接导入到Hbase中,会显得更快速更方便,Hbase中有现成的工具支持来这么做。
这两个工具分别是ImportTSV和complete不离开load。
ImportTSV是用来将日志文件转化成HFile文件的。
1.首先要用ImportTSV生成HFile文件
命令行:hbase$bin/hbase org.apache.hadoop.hbase.mapreduce.ImportTsv -Dimporttsv.separator=","
-Dimporttsv.bulk.output=hfile_simple -Dimporttsv.columns=HBASE_ROW_KEY,cf b hdfs://localhost:9000/user/hadoop/input1/simple.cvs

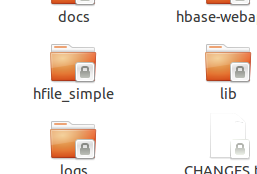
生成的Hbase下面的HFile文件如下图所示:
或者用命令行 :
hadoop jar ${HBASE_HOME}/hbase-version.jar importtsv -Dimporttsv.columns=HBASE_ROW_KEY,CF
-Dimporttsv.bulk.output=/user/
hfile/test_hfile.log tablename /user/log/test.log
需要注意的是上面每行记录的分隔是空格符号,如果是其它符号,比如#,则需要加一个参数-Dimporttsv.separator=#,则语句为:
hadoop jar ${HBASE_HOME}/hbase-0.92.1.jar importtsv
-Dimporttsv.columns=HBASE_ROW_KEY,d:c1,d:c2 -Dimporttsv.bulk.output=/user/
hfile/test_hfile.log -Dimporttsv.separator=# datatsv /user/log/test.log
Completebulkload的作用就是将HFile文件导入到Hbase中,在这里,就将上面生成的HFile文件导入到Hbase表b中。
然后利用命令行:
两种方法:
第一种:
$bin/hbase org.apache.hadoop.mapreduce.LoadIncrementalHFiles <hdfs://storefileoutput> <tablename>
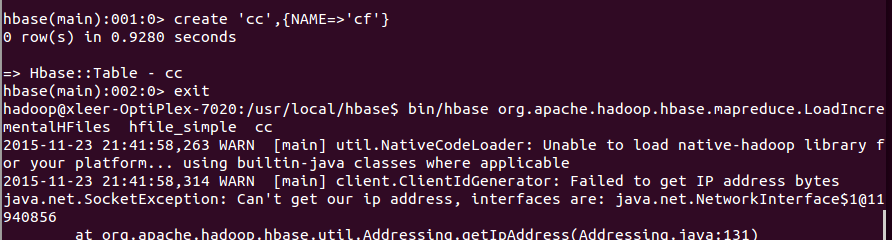
具体代码如下:
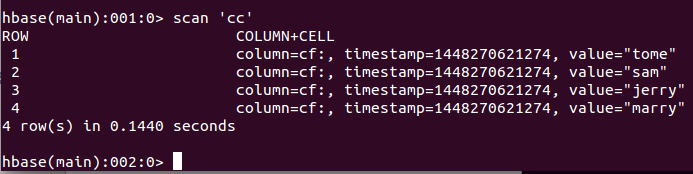
导入数据的结果如图;
第二种方法:(我没用,因为Hbase1.0.0的jar包不知道要用哪一个)
命令如下:
${Hadoop_HOME}$bin/hadoop jar ${HBASE_HOME}/hbase-version.jar completebulkload <hdfs://storefileoutput> <tablename>